Microsoft Speech AI Can Now Simulate Your Voice From A 3-Second Sample

In yet another big advance in AI, Microsoft have revealed a tool that can simulate your voice and speech with just a three-second audio sample to work with.
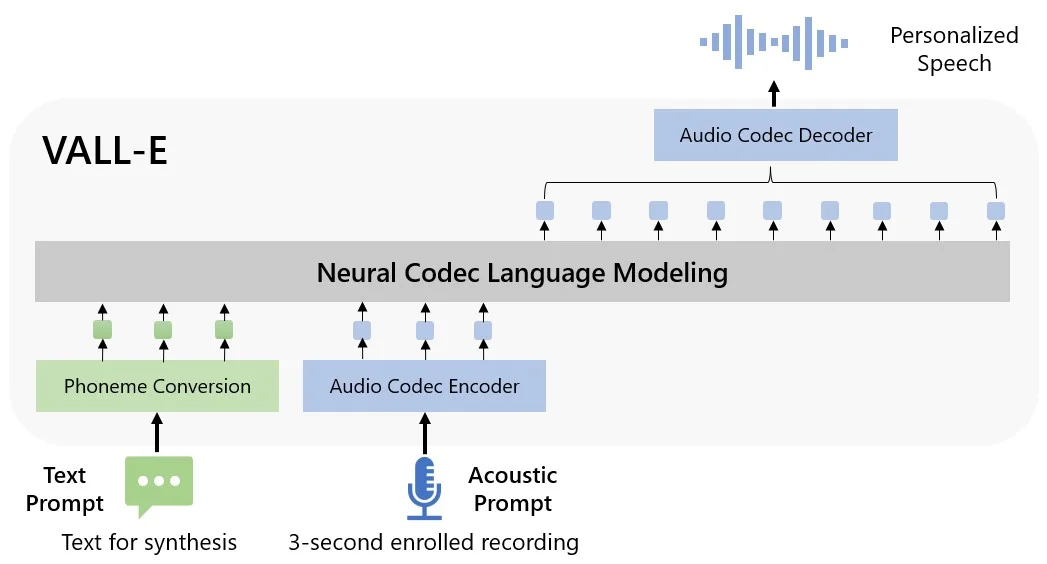
Researchers say the VALL-E tool is a natural codec language model that can synthesise speech, with the aim to improve text-to-speech capabilities so it sounds more natural.
Microsoft say that only a very limited sample of speaking voice is needed for the new tech to deliver the emotion and authenticity inherent in the voice, so if the subject is amused, angry, disgusted or sleepy, VALL-E will attempt to stick to that emotion in its simulation.
It uses tech created by Meta called LibriLight, and currently has 60,000 hours of English language speech from 7000 speakers. Meta first developed the tech to fill drop-outs on audio calls when the signal isn’t up to scratch, but Microsoft want to take it further, potentially helping people who have lost their voice communicate again in their own speech.
Explaining their trials, Microsoft says, “VALL-E emerges in-context learning capabilities and can be used to synthesise high-quality personalised speech with only a 3-second enrolled recording of an unseen speaker as an acoustic prompt.
“Experiment results show that VALL-E significantly outperforms the state-of-the-art zero-shot TTS system in terms of speech naturalness and speaker similarity.
“In addition, we find VALL-E could preserve the speaker’s emotion and acoustic environment of the acoustic prompt in synthesis.”